Statistiques¶
Statistiques¶
Le diagramme circulaire¶
Une fois n’est pas coutume, commençons par le fromage.
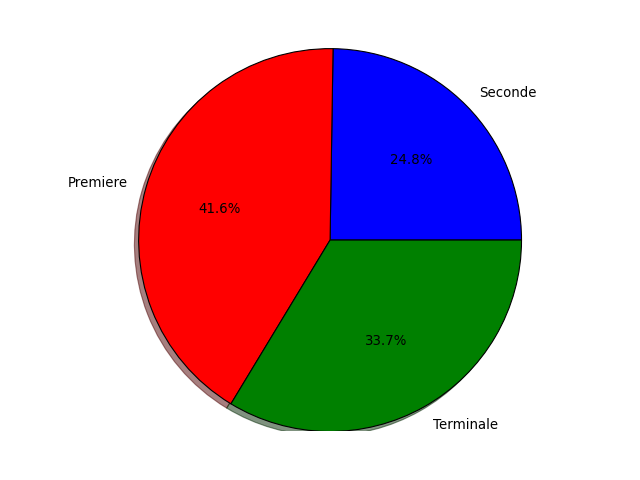
from pylab import *
niveaux = ['Seconde', 'Premiere', 'Terminale']
couleurs = ['b', 'r', 'g']
repartition = [125, 210, 170]
pie(repartition, labels=niveaux, colors=couleurs, autopct='%1.1f%%')
axis('equal')
show()
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}

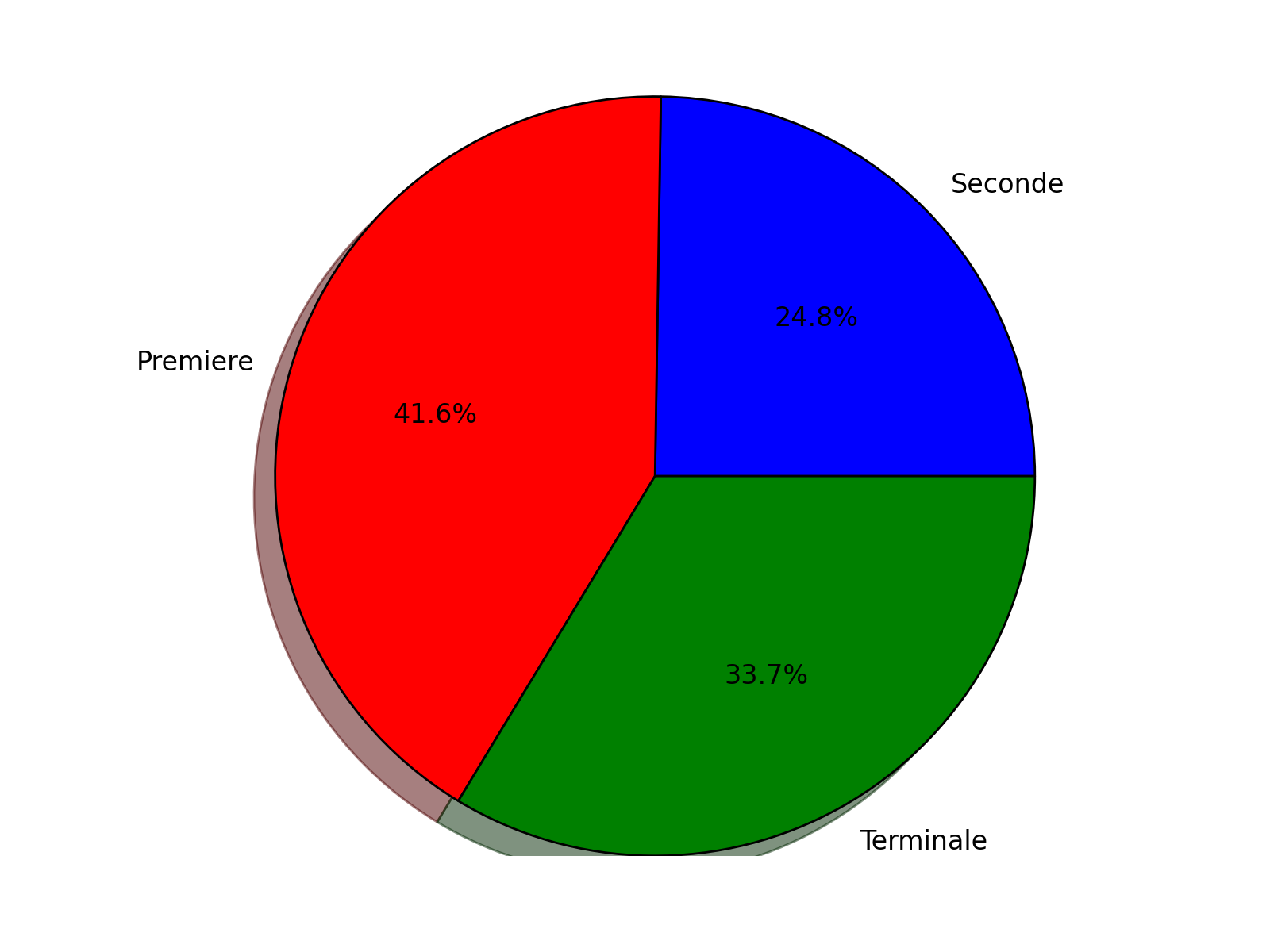
On peut rajouter un peu d’ombre.
from pylab import *
niveaux=['Seconde','Premiere','Terminale']
couleurs=['b','r','g']
repartition=[125,210,170]
pie(repartition,labels=niveaux,colors=couleurs,autopct='%1.1f%%',shadow=True)
axis('equal')
show()
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
On peut aussi aerer les parts.
from pylab import *
niveaux = ['Seconde', 'Premiere', 'Terminale']
couleurs = ['b', 'r', 'g']
repartition = [125, 210, 170]
air = [0.1, 0.1, 0.1] # ajout
pie(repartition, labels=niveaux, colors=couleurs, autopct='%1.1f%%', explode=air)
axis('equal')
show()
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}

Ou faire ressortir une part.
from pylab import *
niveaux = ['Seconde', 'Premiere', 'Terminale']
couleurs = ['b', 'r', 'g']
repartition = [125, 210, 170]
air = [0, 0, 0.1] # modif
pie(repartition, labels=niveaux, colors=couleurs, autopct='%1.1f%%', explode=air)
axis('equal')
show()
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}

L’histogramme¶
Avec classes de même amplitude¶
Ci-dessous, vals est la liste des valeurs de la série statistique et
la variable bins est la liste des extrémités des classes qui sont
ici 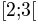 ,
,  et
et  .
.
from pylab import *
vals = [2.4, 2.5, 2.6, 3, 3.1, 3.9, 3.9, 4.2]
bins = [2, 3, 4, 5]
hist(vals, bins)
show()
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}

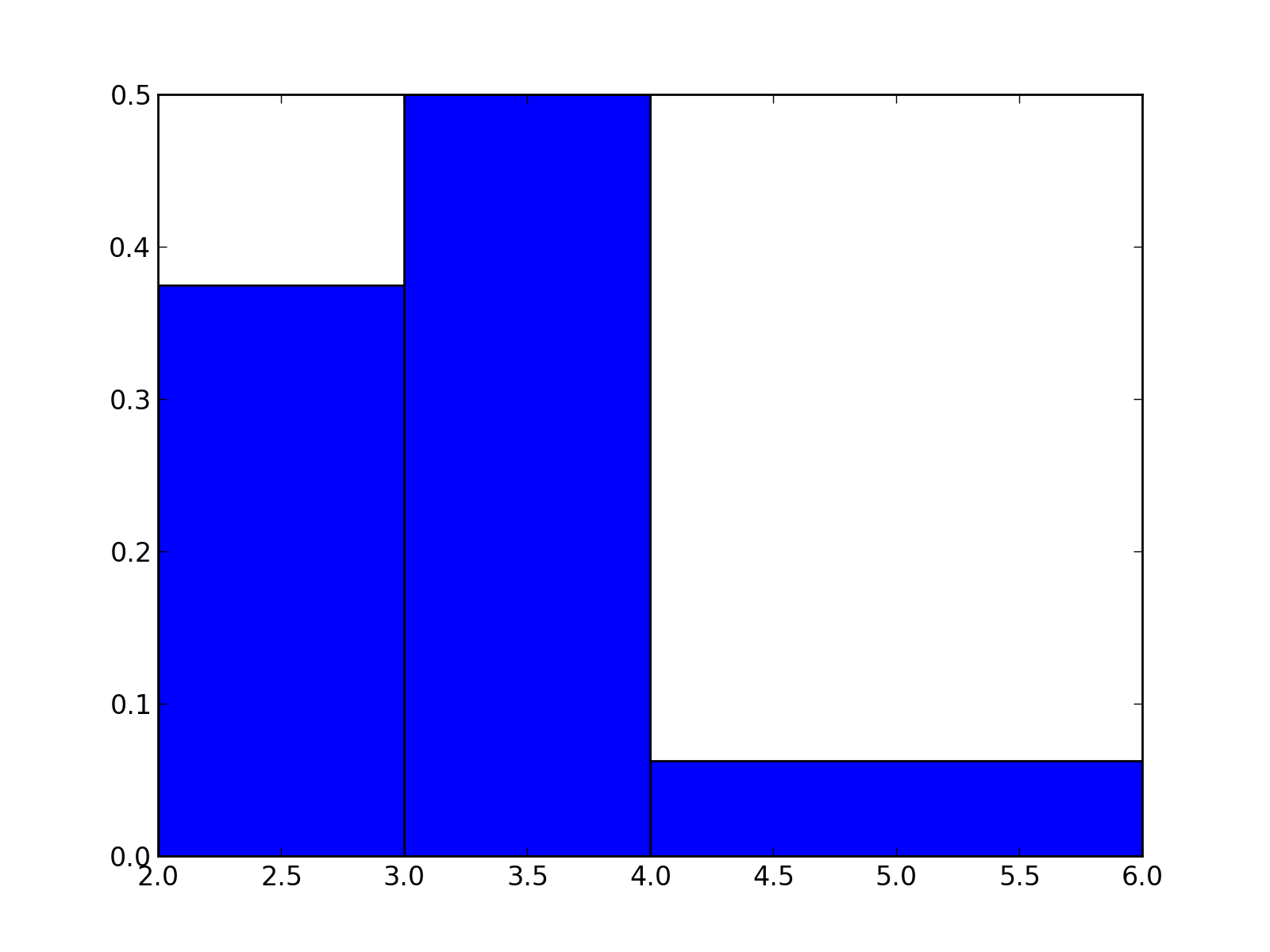
Avec classes d’amplitudes différentes¶
En reprenant l’exemple précédent mais en remplaçant la dernière classe par
 , on obtient :
, on obtient :
from pylab import *
vals = [2.4, 2.5, 2.6, 3, 3.1, 3.9, 3.9, 4.2]
bins = [2, 3, 4, 6]
hist(vals, bins, normed=True)
show()
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
